

皆さんこんにちは。
この「やらかし」Advent Calendarは初年度から拝見させていただいています。
私は業界歴が長く「やらかし」事案はそれなりに経験しています。
お客様との関係もあり、私のトラブル事例も書いて良いのかどうか毎年悩んで止めていましたが、それなりの時間が経過したこともあり教訓を残す意味でもアウトプットすることとしました。
本記事は私の長い業界歴の中でも経験した最大のトラブル事案です。是非お読みください。
背景
当時の状況
本事案は約10年前のこととなります。
私は当時、アプリケーション開発部隊を下支えするインフラ構築チームを率いていました。お客様の要件によってはデータセンターに入ってサーバを設置することもありますし、クラウドを利用することもあります。AWSの案件にも2013年から関わることができていました。
なお私のチームは前年度には7名のメンバーを率いており活況であったのですが、組織再編の煽りを喰らってチーム分割の憂き目に遭ってしまい、この年は私とメンバー2人の3名の小規模チームでした。少人数ながら既存のお客様の保守や追加案件などを細々と対応していた、そんな感じです。
今回のトラブルは、そんな既存のお客様のサーバリプレイス案件で発生しました。
要件
お客様は、BtoBのSaaSサービスを提供している事業者となります。
サービスレベル向上のため、インフラへの投資も惜しまない良いお客様でした。
本システムではVMware vSphere仮想化基盤、ロードバランサーによる負荷分散、データベースも冗長構成、それにDR(ディザスタリカバリ)環境として別センターに設備があるといった可用性向上への取り組みも素晴らしいお客様でしたが、唯一シングルポイントのサーバがありました。ファイルサーバ(NAS)です。
本サーバは、多数のアプリケーションサーバ(主にLinux)からNFSマウントされており、主にエンドユーザーへの請求書(PDF)などが大量に保管されている、結構重要なサーバではありました。
従来からクラスタウェアを使った冗長化ファイルサーバの構成はありましたが、原則として共有ディスクが必要ですし、その場合は共有ディスクがシングルポイントと捉えることができます。またフェイルオーバー時の接続断もあるのでので悩ましいところではありました。
そこで ファイルサーバの無停止での冗長化 や、DR環境への同期ができるソリューションは無いか? お客様から相談があったのがきっかけとなります。
提案内容
そこで私は、前年のAWS案件で採用したツールを思い出します。
当時のAWSには、Amazon EFSやAmazon FSxシリーズのようなファイル共有を司るサービスはありませんでしたので、Amazon EC2上で実現する他ありませんでした。
またAWSで高可用性システムを組む場合、複数アベイラビリティゾーン(AZ)で構成する、Multi-AZ構成で構成することがベストプラクティスとされますが、当然AZを跨ぐ共有ディスクはありません。
そこで私が担当したAWS案件では、LinuxOS上で高可用性のファイルサーバを構築できるOSSを導入し、Multi-AZの高可用性ファイルサーバを実現していました。このシステムは特に問題なく安定稼働していたこともあり、今回の案件でもこれを採用しよう!と思い立ちました。
- AWS案件で安定稼働している
- OSSでなく、商用版を採用することでサポートも得られる
- 製品仕様としてDR環境への転送機能もある
今回の要件にピッタリはまる素晴らしい構成!
と思って意気揚々とお客様に提案し無事受注したのでした。
簡単な構成図も書いておきますね。
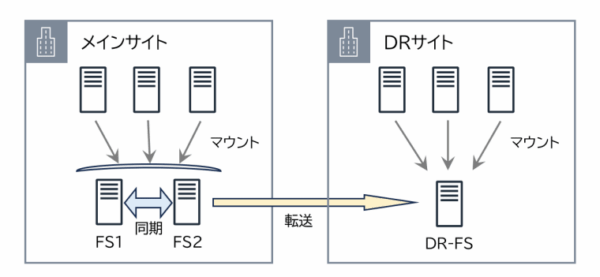
トラブルの経緯
/var が肥大化
構築自体や単体試験は何の支障も無く完了。
初採用であったDRサイトへの転送機能も無事動作しているようです。
その後、月次のメンテナンス日にデータ移行も完了し、予定通りリリースを迎えます。
ところが、それ以降 /var の容量が徐々に肥大化していることに気付きます。
数週間後にはパンクが懸念される状況に陥りました。
徐々に消えていくファイル
パンクが懸念される事態になり、メンテナンスウィンドウである深夜に作業を敢行しました。
まず /var 内の肥大化したディレクトリを他パーティションに待避する対応をしました。
この作業自体はプロジェクトメンバーが実施したため詳細不明ですが、
何とそれ以降、マウントしたサーバ側から見るとファイルが徐々に消えていく(見えなくなる)事象が・・・
※恐らくインデックスが破損してしまったのでしょう。
請求書(PDF)等がどんどん見えなくなっていきます。
かなり拙い状況になってきました。
遂に私がオペミスでトドメを刺す
私の方では、更に /var 内で圧迫している古いログファイルを待避することとし、/home 内に移動しました。
但し誤ってカレントディレクトリに大量のファイルを移動してしまいました。
そこで、サブディレクトリを切ってその中に全ファイルを移動しようとして
# mkdir sub-directory # mv ./* sub-directory/
と打ったつもりが・・・
踏み台サーバ経由で操作性/視認性の悪い環境で作業したせいか、いや23時過ぎの作業で集中力が落ちていたのか、ドットが抜けていることを見落とし
# mkdir sub-directory # mv /* sub-directory/
と命令してしまったのでした・・・
コンソールには見たことのないエラーが大量に発生、急いで CTRL+C で中止しましたが既に後の祭りでした。
何とかならないかと悪あがきしましたが、各種システムフォルダを移動してしまったので、大多数のコマンドすら利きません。詰みました。
対処
結論から先にお伝えしますと、なんとかサービス影響は発生させずに済みました。
当日の暫定復旧
お客様へ緊急の連絡を入れた上で、オペミスで壊していないもう1つの片系で復旧を開始。
サーバの中を捜索したところ、実体のファイルは無傷で残っていました。
そこで(苦渋の決断ですが)復旧スピードを優先し、当該ソフトウェア(OSS)の利用を中止。
Linux OS標準機能のNFSでエクスポートする決断をします。
朝までにマウント側のサーバのマウント切り替えも完了し、メンテナンスウィンドウ中に暫定復旧できました(なお徹夜)
オペミスの自責の念もあり、さらに翌日晩まで稼働状況を目視で確認、結果として2徹となりました。
なおトラブル事案ですので上長にも報告しましたが「大変だねぇ」とのコメントのみ。
そういえば我々はアプリケーション開発組織の中の孤独なインフラチームでした。
その後の対応
その後のメンテナンス日に壊してしまったサーバのOS再インストールを実施。
rsyncでファイル同期する無難な構成に落ち着きました。
DR環境への転送もrsyncで実装。
なお、本構成では手動のフェイルオーバーが必要となりますので、障害時のマウント側の切り替え運用手順、スクリプトを整備し運用側に手順を引き渡し、ひとまず対処は完了となりました。
製品サポート・・・?
そもそも本製品はサポートがあるから採用したのでは? と思いますよね。
勿論トラブル中にも問い合わせしましたよ・・・メールで。
そもそも本製品の製品サポートのサービスレベルを調べたら「3営業日内回答」でした。
ストレージ製品の保守としては、、厳しいですね。。
ガンガン相談したらメーカーさんからは3営業日って書いてあるでしょ、と叱責されました。
そういった経緯もあり、当該ソフトウェアの利用は恒久的に中止となりました。
結果として不要な製品をお客様に買って頂いた形になったことについては、本当に反省してます。
※購入取り消しも相談しましたが無理でした。
なお本トラブル復旧においては、お客様や他アプリケーション開発ベンダーの方々の一致団結があって成し遂げたものと思います。今更ながらご協力いただいた方々、本当にありがとうございました。
この事象から得た教訓
初採用の機能については、ちゃんと検証すること
そもそも何で /var が肥大化したのか。
(一部推測になりますが)DR環境への転送機能が全く使い物にならなかったようで、移行した既存ファイルを処理しきれなかったようです。
確かに、(安定稼働している)AWS案件ではDR転送機能は利用しておらず、初採用でした。
一般的に、アプリケーション開発においては力業(工数掛ければ)「なんとかできる」世界なのかもしれませんが、インフラにおいては要求仕様を満たさないことが発覚すると「どうにもなりません」。
初採用機能においてはちゃんと検証し、要件を満たすかどうか確認しましょう。
操作は2人体制でダブルチェック/むやみにrootで作業しない/相対パスは利用しない
当たり前すぎて恥ずかしいのですが、トラブルで余裕がなくなるとなし崩し的にザル対応なりがちです。
トラブル時にも基本徹底を心がけましょう。
そもそも絶対パスでコマンドを打つ癖を付けていればトドメは刺さなくて済んだはずです。
製品サポートのあり/なしだけでなく、サポートレベルも考慮すること
ここは提案時には盲点でした。
サポートがあることだけを考えており、サポートレベルを考慮できていませんでした。
今回のサーバーにおいてはかなり重要な場所にも関わらず、3営業日というのは無理がありました。
(もし可能であれば)追加費用でサポートレベルを上げるなどの検討も必要です。
困ったことに相談できるよう、自社内に仲間を作ること
当該年度においては、私のチームは3名のみの脆弱な体制。
今回は私が2徹して何とかしましたが、トラブルを起こしてしまうとリカバーが利きません。
できれば困ったときに頼れる仲間を社内で形成しておきお互い助け合うことを検討すべきです。
その後の顛末
無事安定稼働をした後、お客様には謝罪に行きました。
結構なトラブルでしたが、強い叱責を頂くこと無く対応いただき感謝でしかないです。
今回の謝罪は(最後は)コマンド打ち間違いという初歩的な話のため、説明が情けなかったですね。
また私は思うところがありまして、翌年に社内公募制度を利用してクラウド部隊に異動することにしました。
3名チームのリーダーである私が他部署に異動すること、それはつまり事実上チーム解散を意味しますが、悩んだ結果、チームは畳むべきだろうと判断した次第です。
残されるメンバー2人に詫びた上で、チームは解散すべきと考えていることを説明し異動しました。
翌年、その2人も公募で異動しチームはメンバーゼロとなり消滅しました。
この時の判断については今でも色々考えることがありますが、この判断が今に繋がっていると思っています。
最後に
この業界、残念ながら? いろいろクヨクヨしていては心が持たない世界です。
トラブルを起こしてしまった人も(一通り反省した後は)これも糧だと前向きに捉えて生きていって頂ければと思います。
あと、この一件以来、ストレージの中の人は尊敬するようになりました(笑
ファイルがちゃんと保持されているだけでもすごいです!
以上、雑なまとめですがトラブル事案の報告でした。
昔の事案ですが、反面教師として取り組んで頂ければと思います。ありがとうございました。
コメント